
在本文中,我将主要讲讲对unity游戏,RPG游戏,renpy游戏,godot游戏的汉化经验,但放在最开头的,还是对本文中提到的软件的作者们的致谢,正是有了诸位的工作,我们才能来到这个近乎人人皆可做汉化的时代。
首先,在开始作业前,我们首先要明确的是游戏引擎,不同的游戏引擎代表了不同的解包方式,尽管不少游戏不需要解包,更多的是通过注入的方式实现,但这也需要工具的实现,如果不是通用的引擎,那么便只能找办法解包汉化,而这也代表极大的工作量,对于这类游戏往往需要一个真正的汉化组,而非个人汉化。
Sakura模型的部署(非必须)
Sakura模型的翻译质量体感上是gpt3.5-gpt4之间的水平,放在今天大抵是不先进的,但最大的优点就是免费,如果目标是测试自己的脚本,又或者就是单纯的不想花钱,那么sakura便是不二之选。
模型的下载地址是SakuraLLM (SakuraLLM),这里放上国内镜像站的地址,请自行挑选适合自己机器的版本。
笔者推荐使用neavo/OneClickLLAMA: 一键运行 Qwen2.5 SakuraLLM 等本地 LLM 模型项目来实现本地部署,下载解压后,点击两下鼠标就可以实现运行,请按显存来选择使用哪一个脚本。
如果希望能将闲置算力分享出去,那么也可以使用PiDanShouRouZhouXD/Sakura_Launcher_GUI: Sakura模型启动器。
RPG篇
1.mtool及文本导出
首先介绍最简单的工具,MTool,使用它可以完成对大量游戏的引擎的判别,以及,最重要的,对游戏文本的提取。
我认为追求最简单的,最省力的汉化的朋友,就应该首先尝试使用mtool,它提取出来的文本是可以被下文提到的各项工具所支持的,如果打算利用软件本身自带的翻译也是可以的,不过据说不能分享给别的人,所以以分享为目的的朋友建议注意。
请遵循官网教程的1-3步骤,MTool – 玩家专属的游戏翻译与修改工具 | 支持多种主流游戏引擎的智能处理工具,到第4步的时候返回本页,我们接下来将使用其它工具去汉化

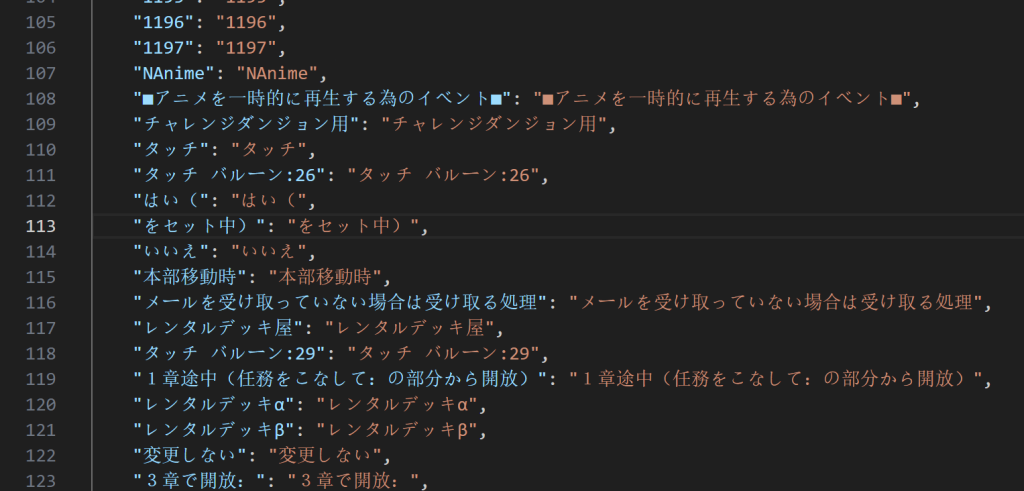
在这个界面点击导出待翻译的原文后,游戏目录下会出现一个名为ManualTransFile.json的文件,这便是游戏内的几乎所有文本,其格式大致如此,冒号前面的是游戏原文,冒号后面的是未来需要替换成中文的
2.翻译工具LinguaGacha
如果个人精力真的足够强悍,是可以手敲着去汉化,不过AI时代的我们不再需要这么做,接下来将介绍两个工具
NEKOparapa/AiNiee: 一款专注于Ai翻译的工具,一键自动翻译RPG SLG游戏,Epub TXT小说,PDF Word MD文档,Srt Vtt Lrc字幕等等复杂长文本。
neavo/LinguaGacha: 使用 AI 能力一键翻译 小说、游戏、字幕 等文本内容的次世代文本翻译器
两个软件都可以下载,也可以都保存下来,尽管软件的UI看着很像,但其内核却是不同的,本文写作的时候,AiNiee有报告说是无法使用Sakura模型,同时笔者测试其它模型的时候也出现了一些的BUG,所以本文将以LinguaGacha作为示范。
下载,解压后打开app.exe文件,将会弹出一个控制台窗口和一个正常的UI界面,不要关闭那个控制台窗口,那是软件的后端,我们可以通过它实时的观测到软件到底在干啥
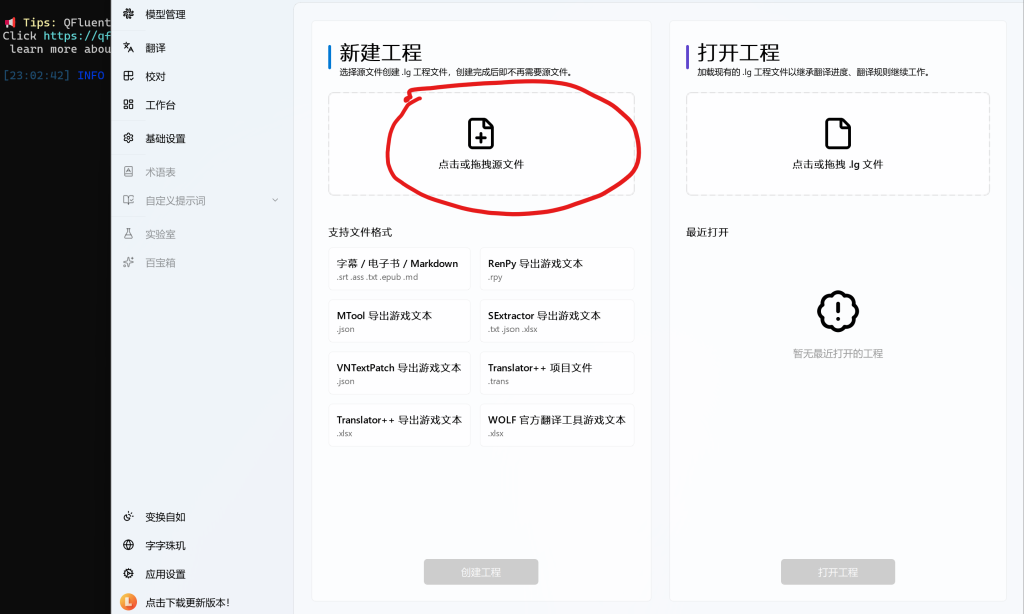
可以看到,软件支持的格式,我们将Mtool导出文件拖入红圈处,然后点击下方的创建工程,它会提示你要新建个lg格式的文件,选择你想放置的位置保存即可
3.API设置
3.1.本地API(Sakura)
进入工程之后,我们首先添加模型,如果本地有部署Sakura模型的,不是很需要在线模型的,点击基础设置,设置Sakura模型
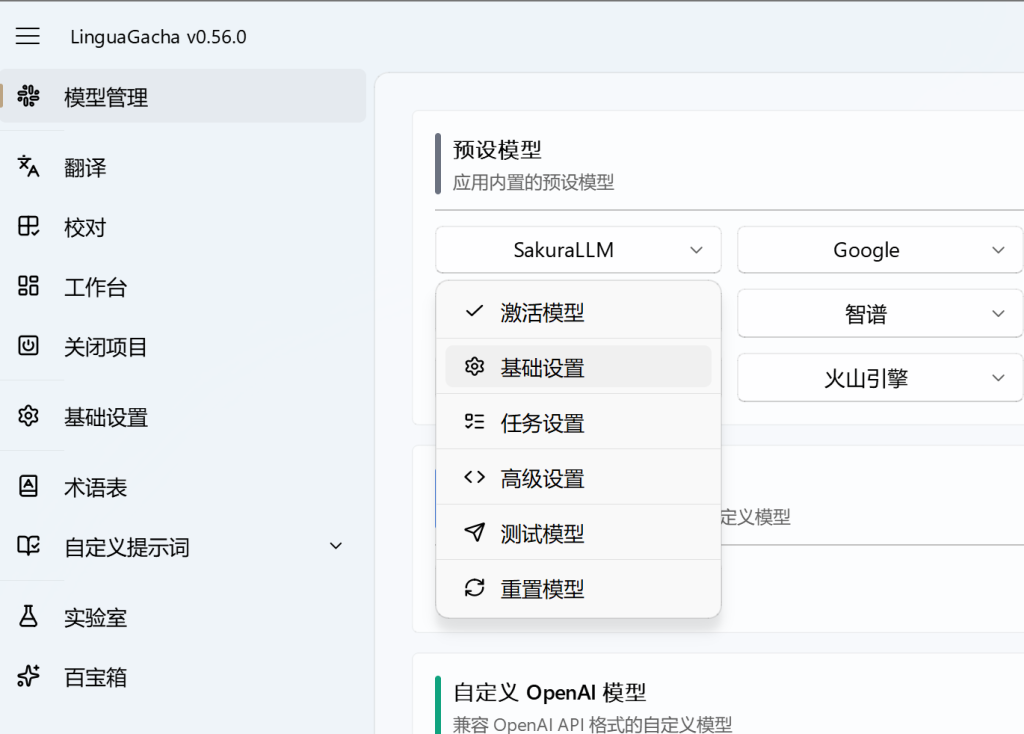
如果没有什么需要特别设定的地方,那么按照默认即可,点击下方的在线获取
选择需要的模型后关闭即可
最后回到最开始,点击激活模型,之后再点击一次测试模型,如果弹出成功,那么便代表设置完成

3.2.在线API(deepseek)
如果本地部署不了Sakura,或者需要更高的速度或是质量,那么我们便需要使用在线API,这里推荐使用deepseek api,尽管deepseek或许在编程之类的项目上比不过那些日新月异的新模型,但翻译工作上则暂时并不需要那些性能,另外deepseek api无审查,且相当便宜
这里是deepseek api的平台,https://platform.deepseek.com/,请注意,API是需要付费的,作为参考,我这边翻译一个11M的文本,吃了大约13块钱,考虑到Mtool可能出现的BUG,建议不要全文翻译后再验证质量,最好在翻译开始后不久就导出当前进度看看效果。
注册完成后,点击左侧API KEYS,选择创建api key
复制并存好你的API key(该KEY仅作展示,教程发表时已经删除)
回到LinguaGacha,选择模型管理——deepseek——基础设置
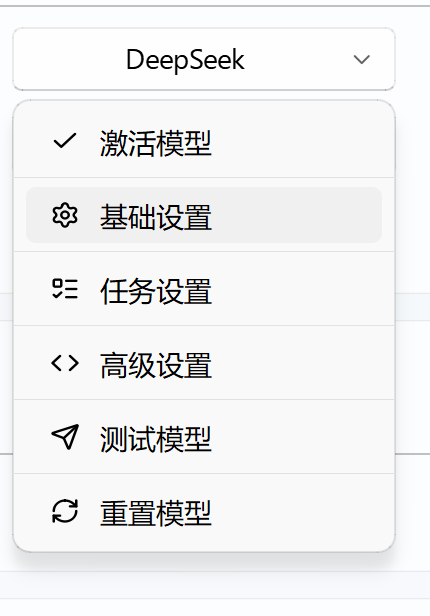
输入你的APIkey后关闭
4.翻译和导回游戏
在这之后,最基础的配置便已经完成,如果没有任何进一步的需求,那么便可以开始翻译,点击左侧翻译——点击开始即可开始,等待翻译结束,如果想提前检查翻译质量点击生成译文即可在不中断翻译的情况下提前导出json文件。
翻译出来的文件会被存放在和工程文件同样名字+_译文的目录里,如果一个工程输出多个翻译文件,那么从第二个开始名字会带上当前时间
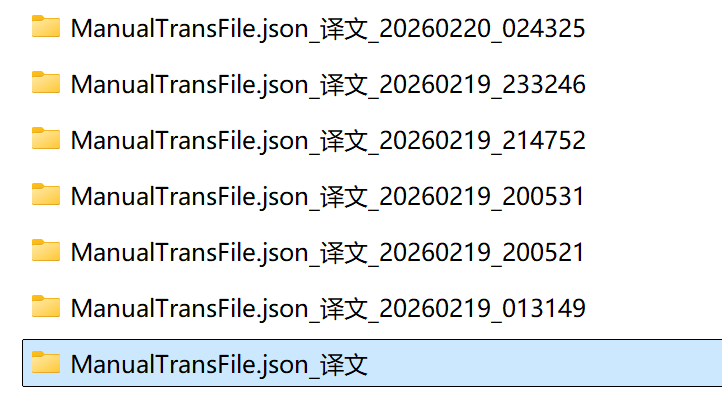
将文件夹内的json文件复制回游戏目录,回到Mtool,点击加载翻译文件,选择你复制回来的翻译文件,然后Mtool便会帮你完成翻译文件的加载和字体的替换。
5.transltor++(适用于mtool导出有bug的情况)
细心的朋友可能发现了,我上文多次提到要小心mtool导出文本有问题的情况,在游戏文本较为复杂,出现了大量的类似\NN[1]之类的占位符的情况下,使用mtool导出会导致句子中的占位符对应的文本位置发生偏移,举例来说原文是“你需要多向爱丽丝小姐学习学习”,但翻译出来可能就变成了“你需要爱丽丝多向小姐学习学习”,出现这种情况的时候,不要浪费时间和金钱跑AI,请直接试着把第一步导出的文件导回去试试,看看日文原文是不是也发生了这样的现象,如果出现了大量这样的现象,还请试试transltor++
Download – Dreamsavior这是官网链接
https://mega.nz/file/awVmmAiT#wOoal8Tue3Y_pRoEKiarSkNMlvEG2p2KWVbUmcIwopo这是官网提供的下载的链接
5.1.创建工程
打开软件后会提示你更新,如果你有资助,那么便可以使用最新版本,如果没有也可以使用公众版本,我们这次使用公众版本。
同样的,可以注意到后面有个Third party application installer,选择你游戏相应的引擎,点击那个对应的蓝色按钮就行。
点击创建新的工程,选择你的游戏游戏引擎

选择你的游戏文件
点击creat project
点击I know the risk,Proceed!
点击右上角的保存按钮,会生成一个trans文件,到这里就完成了上面的第一步mtool及文本导出的步骤,之后的步骤基本上一样,我们直接来到导回游戏的步骤
5.2.导回游戏
在游戏从linguagacha翻译完成后,会导出一个trans文件,这次我们选择打开工程
打开输出的trans文件,点击红圈处的导出
我推荐点击输出到压缩包,不过还是要看具体项目
导出完成后打开压缩包,能看到两个文件夹,但还是看具体项目,能看到多少都不奇怪

在我这边的项目中,将data文件夹放入游戏根目录的www文件夹,覆盖掉同名文件即可。
5.3.查漏补缺
使用translator++出现遗漏的概率不小,因为软件会自动的去识别,认为有些文本不需要,有些文本不能翻译,这些文本会被标红和标蓝,这种情况通常来说需要手动去校对。
不过这边有个讨巧的方案,因为我们使用translator++的翻译实际上可以被视为对游戏本体的修改。
换句话说,如果我们这时候再次导出文本,那么这一次导出的文件就是半汉化的,而之前mtool难以处理的,那些带占位符的文本已经被处理好了。所以我们可以再一次的打开mtool,用mtool导出待翻译的文件,在翻译后再次导入回去即可。
但是要注意,这一次不能再使用LinguaGacha了,因为目前版本的LinguaGacha不带文本的识别,换句话说它会把汉化过的数据再一次发送给大模型让他们翻译,浪费token其次,万一翻译出来的内容顶掉了原来的内容,那么我们之前的步骤就前功尽弃了。
这一次的汉化我们需要使用NEKOparapa/AiNiee,ainiee自带语言识别,在开始任务前会识别待翻译的文件,将我们已经完成汉化的部分从任务序列中摘出去,完成剩余部分的查漏补缺。ainiee的UI和linguagache基本一致,就不赘述,请参照上方linguagacha的教程。
unity篇
1.xunityautotranslate插件
目前来说unity游戏的翻译笔者能见到的基本上都切换到基于xunity翻译了,确实有通过解包实现翻译方法,大致上通过这些软件AssetStudio、UABEA、dnSpy、UnityEX,如果要实现类似图片的汉化,那么解包就是必须的了,但如果只追求看懂,那么使用xunity便可以完成。
xunity的原理是通过注入 Unity 游戏 → 拦截文本 → 发送给翻译接口 → 替换原文本显示的原理实现,所以如果游戏有反作弊,请不要尝试这个插件,建议等待官方翻译,或者采用外挂的翻译方案。
如果目标是采用sakura模型来翻译,并且也只打算翻译,那么可以参照本人以前写的教程来实现XUnity.autotranslate调用Sakura翻译大模型
2.需要打补丁的情况(建议看看)
如果有打算加入补丁,那么则建议使用beplnex插件,具体补丁之类的建议参照这位大佬的博客unity游戏插件去码 | Eikanya‘s Blog,这位大佬写了很多篇有关的博客,另外如果这些插件不管用,也为您指向另一个方案bo3b/3Dmigoto,以及使用这个插件的教程虚幻(及Unity)游戏去码-使用3Dmigoto【最简单方便直观的一集】_哔哩哔哩bilibili_教程,这里只讲解翻译插件的使用。
2.1.下载beplnex
使用beplnex情况下,需要下载对应游戏版本的beplnex插件,请先确认游戏文件夹内是否有名字带Mono的文件夹,有的情况下我们一般下载
https://github.com/BepInEx/BepInEx/releases/download/v5.4.23.5/BepInEx_win_x64_5.4.23.5.zip
如果没有那么代表游戏是il2cpp版本,或者上面的稳定版的补丁不起作用的情况下,请前往下方链接下载测试版,unity引擎更新到6000往后,基于beplnex的翻译方案需要多试试不同版本的,偶尔会有惊喜,不过一般从最新版本来就行
BepInBuilds – BepInEx Bleeding Edge
将文件解压到游戏根目录,运行一次游戏,确认没有报错的情况下继续下一步
2.2.下载beplnex版本的xunity插件
之后按游戏版本下载对应的xunity插件
mono版本下载
il2cpp的版本下载
下载完成后直接解压到游戏根目录,运行一次游戏,关闭
2.3修改配置文件
前往游戏根目录——Beplnex——config——AutoTranslatorConfig.ini
按XUnity.autotranslate调用Sakura翻译大模型文内的内容修改配置文件
前往游戏根目录——Beplnex——plugins——XUnity.AutoTranslator——Translators,将fkiliver/SakuraTranslator的dll文件放入里面。
如果不打算使用sakura模型,可以试试NothingNullNull/XUnity.AutoLLMTranslator这个插件,按readme修改配置文件即可。
运行游戏,确认翻译是否生效。
renpy篇
renpy引擎对翻译工作可以说是非常友好,但那大体上是对作者来说的,不过对翻译者来说也有了非常不错的工具,我很喜欢这位大佬的工具马老师的小课堂的个人空间,非常好用,这是大佬提供的网站的地址Renpy游戏AI翻译器,只能说作者已经提供了非常完整的视频和文字教程,我不认为我能做的比大佬更好,就不再画蛇添足了
建议参照大佬的这一版教程
Renpy游戏AI翻译器第18版介绍-全新翻译_哔哩哔哩_bilibili
在这里附上我个人以前的文章对renpy游戏汉化的经验,如果有什么问题可以去看一下,说不定有用。
godot篇
首先警告,目前对godot的支持并不完善,基本上等同于需要将游戏解包再封包回去,需要汉化者至少要会配置python环境且能熟练利用AI解决问题,另外失败的可能性相当高,请做好准备。
1.解包
依旧是对游戏的解包,我们需要GDRETools/gdsdecomp: Godot reverse engineering tools这个工具来对游戏进行解包,但偶尔还是会看到作者真的做了加密,那种情况下就没有办法了,建议用外挂式的翻译。
打开软件后点击OK,点击左上方的RE Tools
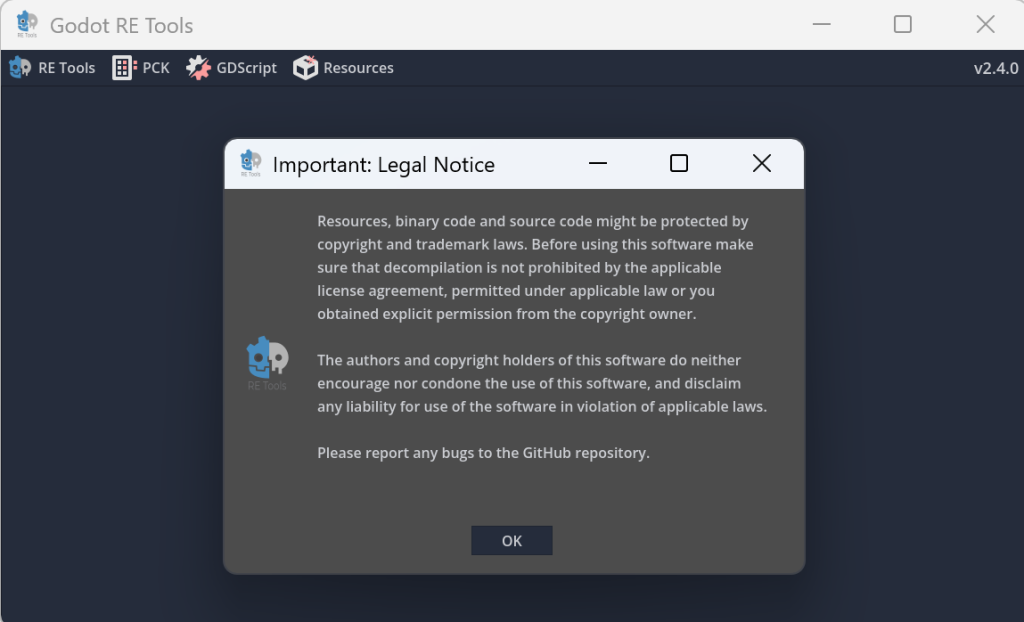
选择recover project
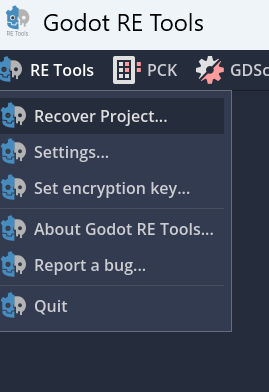
选择到游戏文件,一般是exe文件,会自动完成解包
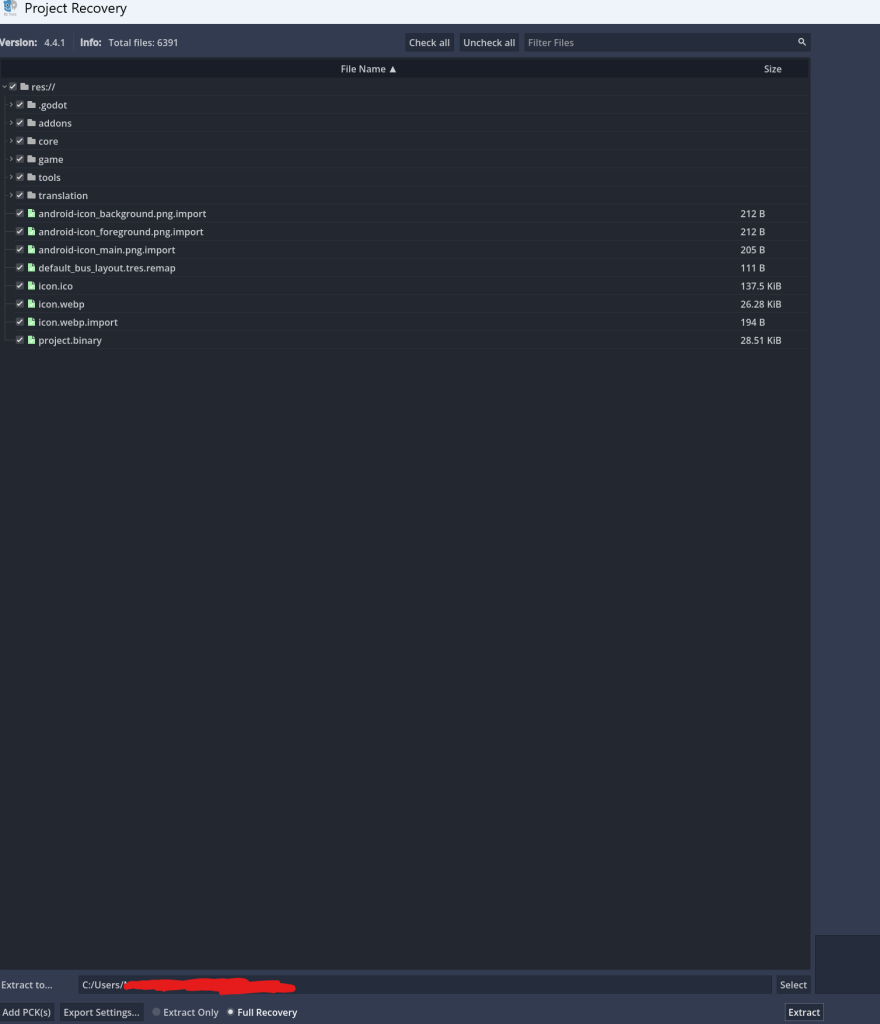
点击下方的extract,会将文件导出到你指定的文件夹
打开文件夹,便能看到translation文件夹,其内部文本以po格式存在,有专门的可以对po文件翻译的软件Poedit Translation Editor — Poedit,但这样做效率过低,我们采用这个工具pescheckit/python-gpt-po,它可以帮助我们将翻译这个文件。
打开终端,,输入
pip install gpt-po-translator
$env:DEEPSEEK_API_KEY="your key"//注意,这个命令是用于在当前窗口中使你的环境变量生效接着打开这个po文件,使用正则方式搜索msgstr “.*”,将其替换为msgstr “”,将”Language: en\n”这一行修改为”Language: cn\n”
回到终端
gpt-po-translator --provider deepseek --folder . --lang cn -v等待翻译完成,翻译可以中断,点按ctrl+c即可暂时停下工作并保存当前进度。
如果不想修改ui,那么可以把文件名改成目前已有的文件名,顶掉原有的翻译,到时候回到游戏选择顶掉的语言即可。
2.封包(不保证成功)
前往官网下载godotDownload for Windows – Godot Engine,解压后打开不带console的那个exe文件
点击导入——选中解包出来的文件夹——找到project.godot——点击打开
点击导入
无视掉所有报错和依赖警告,除非你能解决,强硬的打开项目
点击右上角的项目——导出
点击添加,选择你需要的平台
点击右下角的管理导出模板
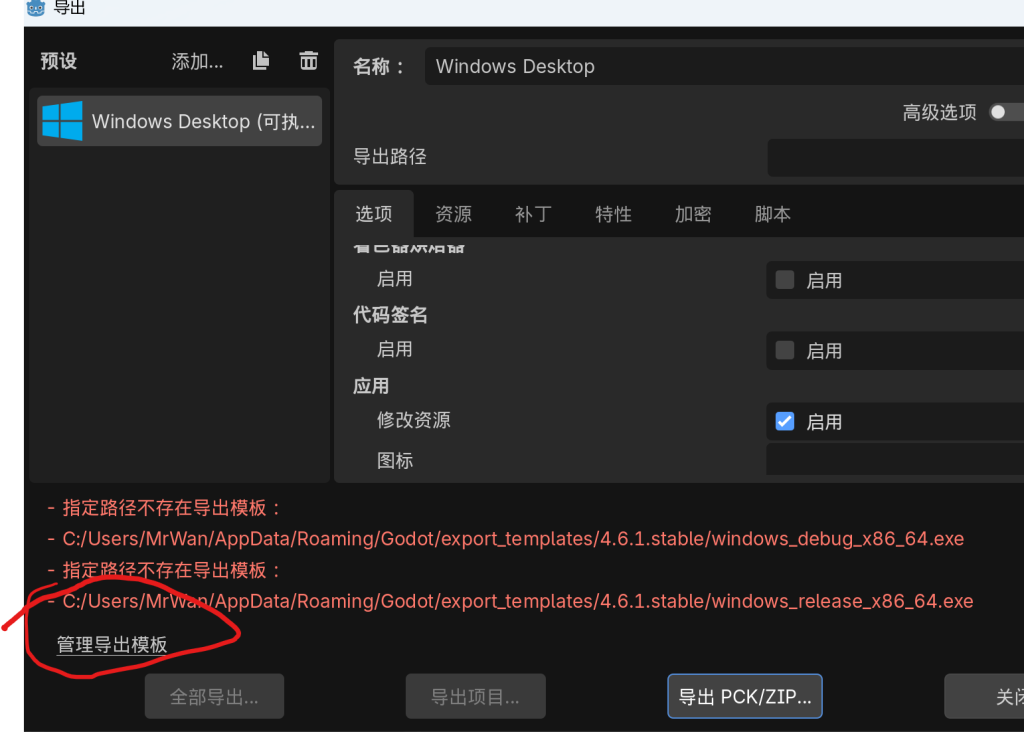
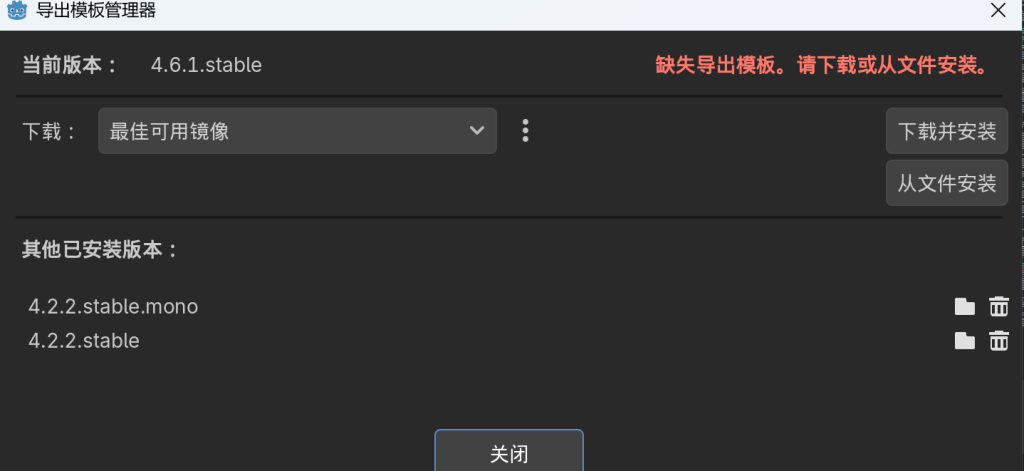
如果处于离线模式,请点击连接,如果已经正常,那么点击下载并安装即可
回到导出,点击导出项目
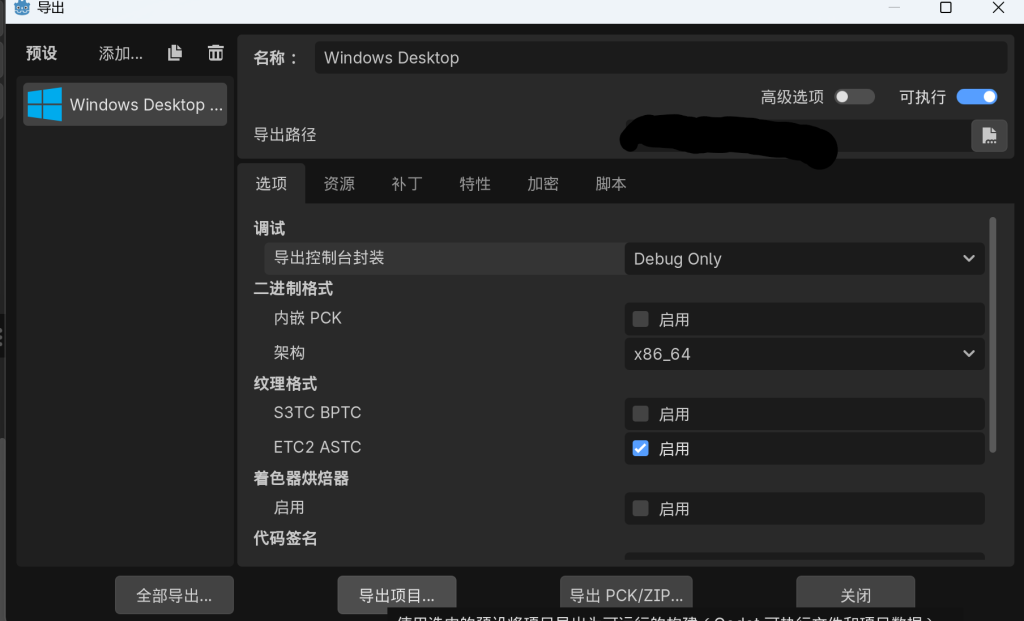
然后祈祷吧,祈祷能跑,或者转头回去尝试修理下那些报错和bug。
另外一个奇妙的小知识,可能导出来的文件无法单独跑,但如果放在解包出来的那个充满了项目文件的文件夹中,则不知为何,能跑。
进阶:术语表的制作
如果只是想简单的翻译游戏,那么,术语表不是必须的,但如果你面对的游戏会更新,又或者你需要提供一份质量较高的翻译,那么,术语表便显得非常重要。
1.介绍术语表软件KeywordGacha
neavo/KeywordGacha: 使用 AI 能力一键分析 小说、游戏、字幕 等文本内容并生成术语表的次世代翻译辅助工具
通过这个软件可以以较低的时间成本生成较高质量的术语表,其UI和LinguaGacha类似,添加API的部分不再赘述,请前往RPG篇的第三节,在这个部分不要用Sakura,建议使用deepseek v3或者deepseek r1。
2.软件的使用
需要注意的是软件的前置替换,强烈建议导入,可以提升术语表初翻的质量
其次是提示词,可以在这里添加一些背景描述,也是同样的可以提升初次翻译的质量
3.查漏补缺和修正
翻译完成后,初版的术语表可能会有不少翻译的质量不行,但数量不多,按个人经验,约1300条中个人大约修正了20-30条。
修正的时候可以把输出的json文件发送给聊天式的ai,让他们提出修改意见,建议多问几家ai。
妥协方案
就像各位所看到的,是的,不能简单汉化的游戏数量相当庞大,godot的汉化只能说提供思路和介绍工具,说不上教程,另外类似虚幻等别的引擎的汉化也没有写入教程。
对于这类游戏,我们能做的也只有OCR+外挂式翻译,也就是经典的团子翻译器。
不过话又说回来,团子虽然在美观和易用性上确实不错,但自由度不够,ocr只有性能较差的本地ocr和在线ocr可选,所以对于追求自由度的朋友,这里推荐LunaTranslator。
这两类软件都有比较充足的教程,不做赘述,还请前往B站搜索关键词。

